
50年前,RAND公司开发了一款图形输入语言系统:Graphical Input Language software system (GRAIL)。在1966年的RAND备忘录中,GRAIL旨在:提供一种方法可以让用户直接的,自然的,和容易的处理他们的问题。
用户使用笔式仪器和平板电脑与GRAIL沟通。GRAIL没鼠标,没键盘,没按钮,没有操纵杆,也没有其他相关的工具。当用户想在屏幕上有一个方框,他们就画一个方框。当用户需要文本在屏幕上,他们就会手写文本。当你今天去翻当年的demo,它依然让人感觉到优雅和神奇。
RAND平板电脑
人们使用RAND电脑与GRAIL互动。用类似笔的仪器将系统的所有输入绘制到RAND平板电脑的表面上。平板电脑有较高的分辨率,使其能够精确地数字化超过一百万个离散笔位。压敏开关安装在笔尖上,每4毫秒将触笔的位置报告给GRAIL作为一对(x,y)坐标。
用户通过RAND平板电脑与阴极管(CRT)显示器,和计算机通信。当有书写动作:笔按在平板电脑上时,笔中的开关关闭,从而通知中央处理单元(CPU) “下笔动作” 。当笔被抬起时,笔开关打开,从而通知CPU“抬笔”动作。当笔在书写表面上移动时,识别方案于每4毫秒反馈其所在的位置。
平滑
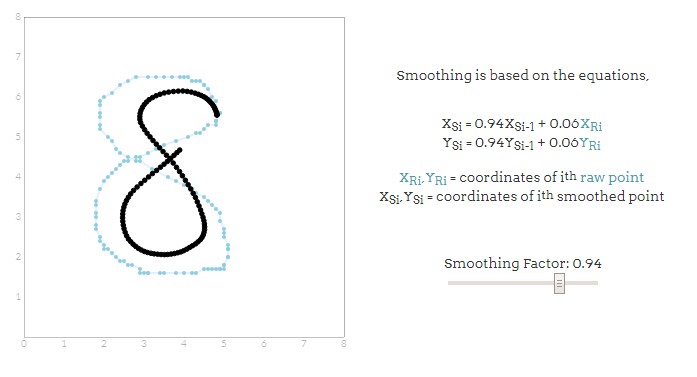
你可能已经注意到,开始的记录会有难看的微小噪点和锯齿形状。原因是:平板电脑只能反馈离散网格上笔的位置。这意味着,即使是平滑的曲线,也会在被平板电脑捕捉后不可避免的包含锯齿状噪点。
Groner决定平滑输出。下图可以让你了解像素化或离散化对绘制笔迹滑动的影响。图一为实际笔迹放大的图,图二为图一经过平滑之后呈现的图。
图一:
图二:
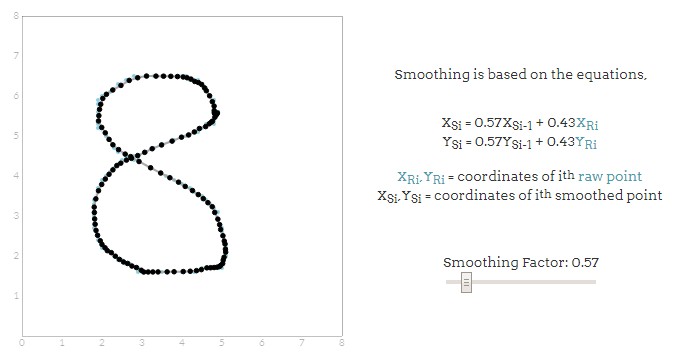
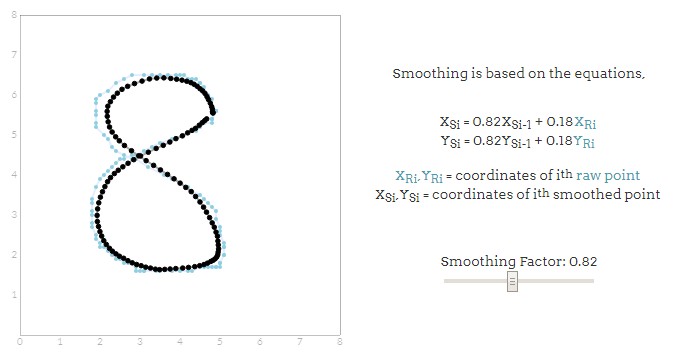
怎么实现平滑呢?平滑是通过缩短该点与左边最邻近值的距离产生。这种简单的平滑方案允许我们保持笔画的整体形态的同时消除不必要的锯齿数据。但请注意,平滑是个破坏性的过程,因此选择合适的平滑因子至关重要。以下分别是不同平滑因子得出的效果,蓝线为原始笔记,灰色线为经过平滑之后的笔记,来感受一下:
平滑因子为25%时:

平滑因子为50%时:

平滑因子为75%时:

可以看出,平滑因子不同,收缩比例不同,平滑效果不一样。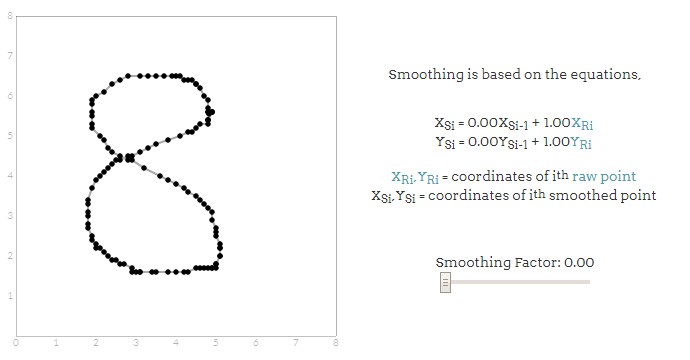
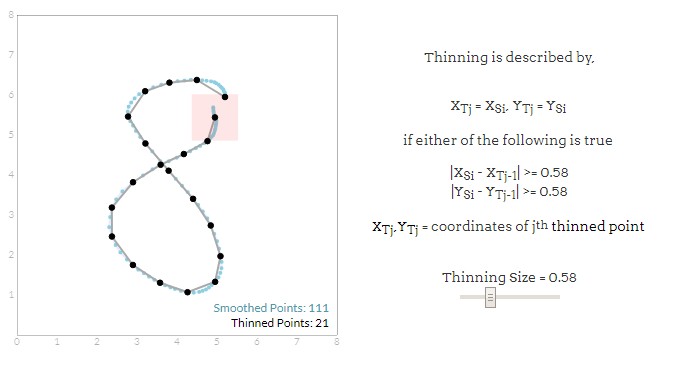
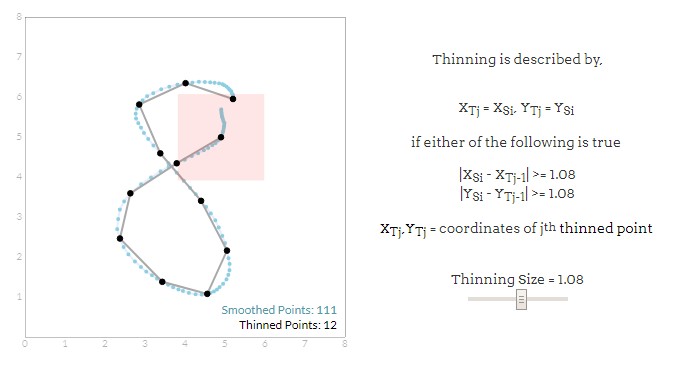
细化
你可能会发现有大量密集的点,尤其是在平板电脑上非常缓慢移动的时候。我们关心笔记的形状,所以大多数的点是不必要的。由此细化的原理为:以第一个数据点为中心,绘制一个正方形,位于该区域的所有非中心点都被丢弃,然后将此正方形移动到下一个落在正方形以外的点上,重复该过程。方形的大小决定了笔划变薄的程度,如下图所示:


Groner发现,即使丢弃了大约70%的原始数据点,他也能取得令人满意的结果。

曲率
曲率是最明显的轨道特征,它与位置和大小无关,但它描述了轨道的形状。在平滑和稀疏输入之后,为每个数据点分配方向。有点令人震惊的是,Groner发现在描述笔画曲率时只考虑基本方向就足够了。因此,每个点被认为是向上,向下,向左或向右移动的结果。我们可以用矩形来测绘这种方向的变化:如果此矩形宽于高,则该点必须表示向左或向右移动。如果矩形高于宽度,则该点必须是向上或向下移动的结果。
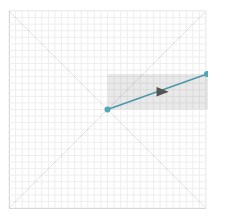
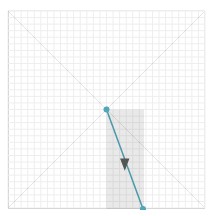

如果相同的方向连续出现两次,并且与序列中最后一个方向不同,则将其保存,否则,丢弃该方向。
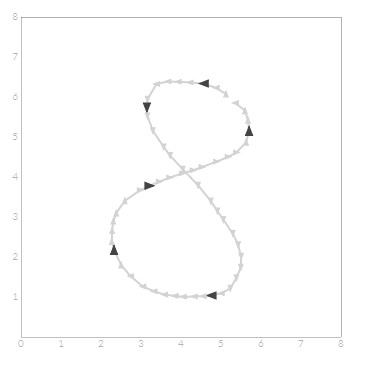
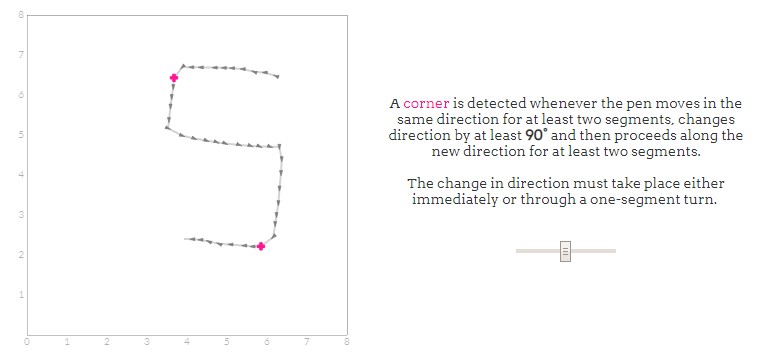
转角
虽然可以使用每个笔划的曲率来对用户的意图做出明智的猜测,但是仅使用方向信息不能将一些符号彼此区分开。例如,“ 5 ”和“ S ”可以这样绘制,即两者都将产生相同的方向段◀▼▶▼◀。同样,圆形和矩形也可能产生▶▼◀▲▶。Groner决定使用角落的存在或不存在来解决这些模棱两可的问题。例如,“ 5 ”通常用符号左侧的一个或两个角绘制,而“ S ”通常会在没有任何角落的情况下绘制。同样,通过检查角的存在,可以将矩形与圆区分开。
通过检测方向改变的程度和区域可以标出corner。例如:
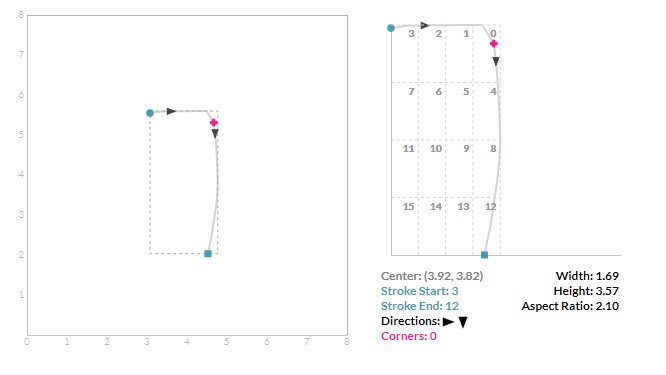
尺寸和位置特征
该描述允许我们轻松回答诸如“用户是否开始在左上方绘制此符号,并在右下方停止绘图?”之类的问题。如果此问题的答案为是,则用户很可能有意绘制2或ž。“用户是否将笔从表面非常靠近开始绘制的位置抬起?”如果是这样,那么用户可能会想要画一个像O或8那样的闭合笔画。笔划描述还捕获笔画的简单特征,如宽度,高度和纵横比。这些功能使我们能够回答诸如“你会将符号描述为胖还是瘦?”这样的问题。这个问题的答案可能有助于我们区分7和1。
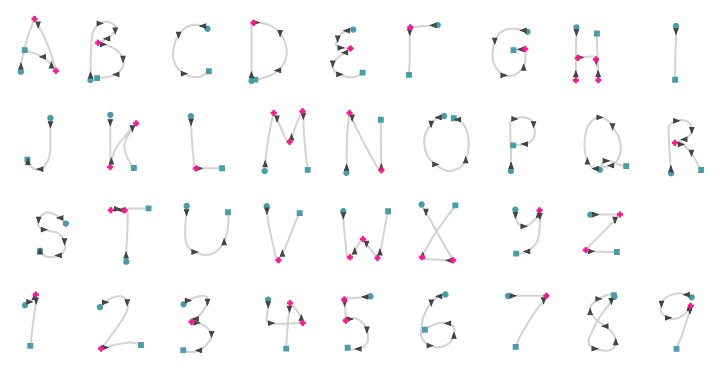
字符识别
符号的识别是基于数据序列集的决策过程。在决策过程的每一步都有几个潜在的识别。其中通过关键特征来消除不可能的项。因此决策方案具有树形结构。
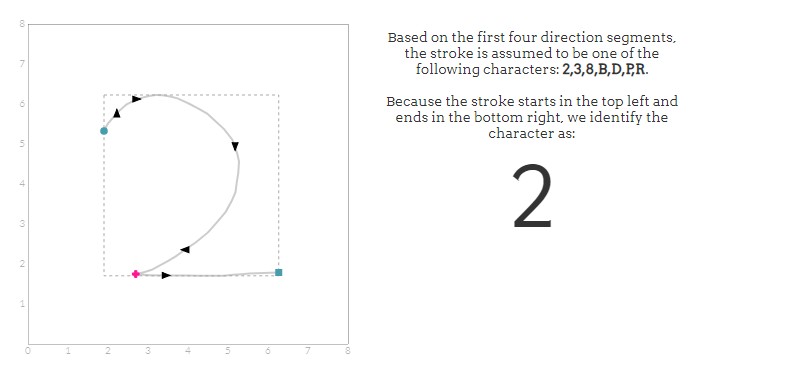
识别器首先根据笔划的前四个主要方向生成潜在字符列表。通常不会因为这个元素就排除了所有不可能集合。我们将留下潜在字符列表。例如,以▶▼◀▲开头的笔划可能最终为O,2或3。
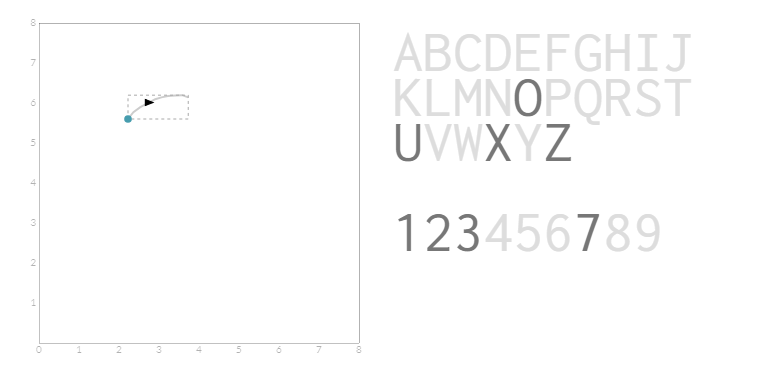
虽然在绘制给定字符时大都遵循一般形状,但Groner的方法足够强大,以便在绘制字符时允许大量的变化和异常。例如,以下所有笔划将被标识为数字3。

以下为实例流程:
后记
为什么我要翻译这篇文章,这个算法看起来是50年前“老旧”的算法。但是50年前就有人用机器学习算法,就好像上个月看的《夏日大作战》为2009年上映的电影。2009年我在干啥?我在玩祖玛,听着《大哥》的英文版玩祖玛。用老旧的台式机,“极端”的硬件环境向同学考各种资源,憧憬着有一天我有自己的家,并且住在海边,就像现在这样。
算法并不是要让人觉得这是个很高深的玩意儿,算法是要更好的让人享受生命的过程,不论是对coders还是users。